
Deep learning is witnessing a growing history of success, however, the large/heavy models that must be run on a high-performance computing system are far from optimal. Artificial intelligence is already widely used in business applications. The computational demands of AI inference and training are increasing. As a result, a relatively new class of deep learning approaches known as quantized neural network models has emerged to address this disparity. Memory has been one of the biggest challenges for deep learning architectures. It was an evolution of the gaming industry that led to the rapid development of hardware leading to GPUs that enables 50 layer networks of today. Still, the hunger for memory by newer and powerful networks is now pushing for evolutions of Deep Learning model compression techniques to put a leash on this requirement, as AI is quickly moving towards edge devices to give near to real-time results for captured data. Model quantization is one such rapidly growing technology that has allowed deep learning models to be deployed on edge devices with less power, memory, and computational capacity than a full-fledged computer.
How did AI Migrate from Cloud to Edge?
A computer examines visual data and searches for a specified set of indicators, such as a person’s head shape, depth of their eyelids, etc. A database of facial markers is built, and an image of a face that matches the database’s essential threshold of resemblance suggests a possible match. Face recognition technologies, such as machine vision, modelling and reconstruction, and analytics, require the utilization of advanced algorithms in the areas of Machine Learning – Deep Learning and CNN (Convolutional Neural Network), which is growing at an exponential rate.
Edge AI mostly works in a decentralized fashion. Small clusters of computer devices now work together to drive decision-making rather than going to a large processing center. Edge computing boosts the device’s real-time response significantly. Another advantage of edge AI over cloud AI is the lower cost of operation, bandwidth, and connectivity. Now, this is not easy as it sounds. Running AI models on the edge devices while maintaining the inference time and high throughput is equally challenging. Model Quantization is the key to solving this problem.
The need for Quantization?
Now before going into quantization, let’s see why neural network in general takes so much memory.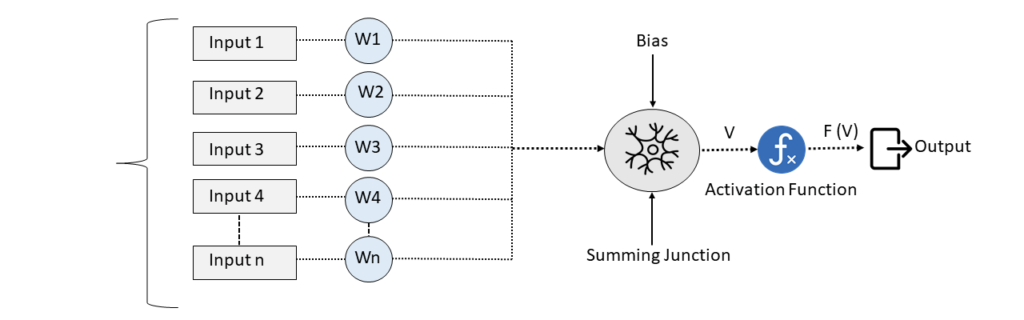
Elements of ANN
As shown in the above figure a standard artificial neural network will consist of layers of interconnected neurons, with each having its weight, bias, and activation function. These weights and biases are referred to as the “parameters” of a neural network. This gets stored physically in memory by a neural network. 32-bit floating-point values are a standard representation for them allowing a high level of precision and accuracy for the neural network.
Getting this accuracy makes any neural network take up much memory. Imagine a neural network with millions of parameters and activations, getting stored as a 32-bit value, and the memory it will consume. For example, a 50-layer ResNet architecture will contain roughly 26 million weights and 16 million activations. So, using 32-bit floating-point values for both the weights and activations would make the entire architecture consume around 168 MB of storage. Quantization is the big terminology that includes different techniques to convert the input values from a large set to output values in a smaller set. The deep learning models that we use for inferencing are nothing but the matrix with complex and iterative mathematical operations which mostly include multiplications. Converting those 32-bit floating values to the 8 bits integer will lower the precision of the weights used.
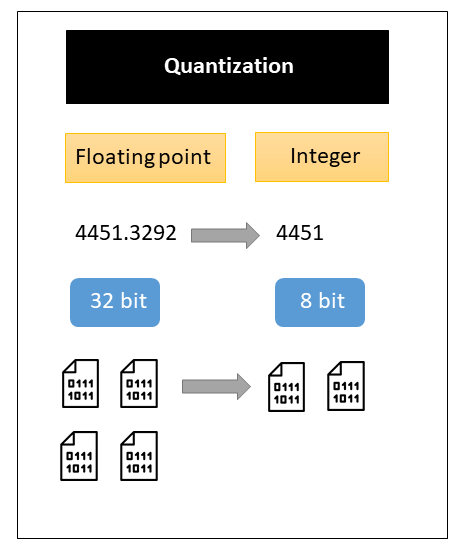
Quantization Storage Format
Due to this storage format, the footprint of the model in the memory gets reduced and it drastically improves the performance of models. In deep learning, weights, and biases are stored as 32-bit floating-point numbers. When the model is trained, it can be reduced to 8-bit integers which eventually reduces the model size. One can either reduce it to 16-bit floating points (2x size reduction) or 8-bit integers (4x size reduction). This will come with a trade-off in the accuracy of the model’s predictions. However, it has been empirically proven in many situations that a quantized model does not suffer from a significant decay or no decay at all in some scenarios.
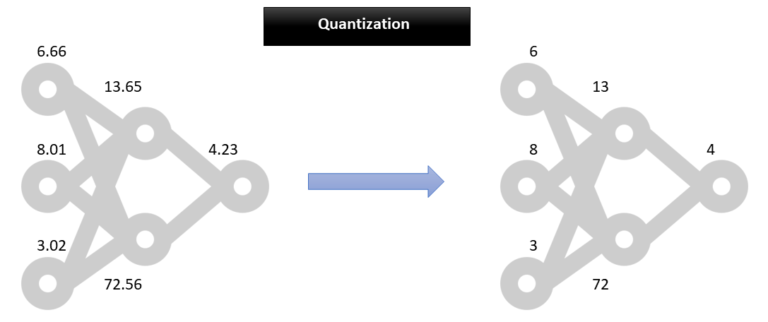
Quantized Neural Network model
How does the quantization process work?
There are 2 ways to do model quantization as explained below:
Post Training Quantization:
As the name suggests, Post Training Quantization is a process of converting a pre-trained model to a quantized model viz. converting the model parameters from 32-bit to 16-bit or 8-bit. It can further be of 2 types. One is Hybrid Quantization, where you just quantize weights and do not touch other parameters of the model. Another is Full Quantization, where you quantize both weights and parameters of the model.
Quantization Aware Training:
As the name suggests, here we quantize the model during the training time. Modifications are done to the network before initial training (using dummy quantize nodes) and it learns the 8-bit weights through training rather than going for conversion later.
Benefits and Drawbacks of Quantization
Quantized neural networks, in addition to improving performance, significantly improve power efficiency due to two factors: lower memory access costs and better computation efficiency. Lower-bit quantized data necessitates less data movement on both sides of the chip, reducing memory bandwidth and conserving a great deal of energy.
As mentioned earlier, it is proven empirically that quantized models don’t suffer from significant decay, still, there are times when quantization greatly reduces models’ accuracy. Hence, with a good application of post quantization or quantization-aware training, one can overcome this drop inaccuracy.
Model quantization is vital when it comes to developing and deploying AI models on edge devices that have low power, memory, and computing. It adds the intelligence to IoT eco-system smoothly.
At MosChip, we provide AI and Machine Learning services and solutions with expertise on cloud platforms accelerators like Azure, AMD, edge platforms (TPU, RPi), NN compiler for the edge, and tools like Docker, GIT, AWS DeepLens, Jetpack SDK, TensorFlow, TensorFlow Lite, and many more targeted for domains like Multimedia, Industrial IoT, Automotive, Healthcare, Consumer, and Security-Surveillance. We can help businesses to build high-performance cloud-to-edge Machine Learning solutions like face/gesture recognition, human counting, key-phrase/voice command detection, object/lane detection, weapon detection, food classification, and more across various platforms.
About MosChip:
MosChip has 20+ years of experience in Semiconductor, Embedded Systems & Software Design, and Product Engineering services with the strength of 1300+ engineers.
Established in 1999, MosChip has development centers in Hyderabad, Bangalore, Pune, and Ahmedabad (India) and a branch office in Santa Clara, USA. Our embedded expertise involves platform enablement (FPGA/ ASIC/ SoC/ processors), firmware and driver development, BSP and board bring-up, OS porting, middleware integration, product re-engineering and sustenance, device and embedded testing, test automation, IoT, AIML solution design and more. Our semiconductor offerings involve silicon design, verification, validation, and turnkey ASIC services. We are also a TSMC DCA (Design Center Alliance) Partner.
Stay current with the latest MosChip updates via LinkedIn, Twitter, FaceBook, Instagram, and YouTube





