
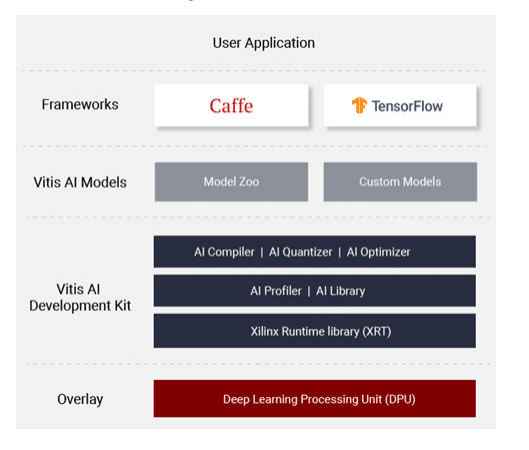
VITIS is a unified software platform for developing SW (BSP, OS, Drivers, Frameworks, and Applications) and HW (RTL, HLS, Ips, etc.) using Vivado and other components for Xilinx FPGA SoC platforms like ZynqMP UltraScale+ and Alveo cards. The key component of VITIS SDK, the VITIS AI runtime (VART), provides a unified interface for the deployment of end ML/AI applications on Edge and Cloud.
Vitis™ AI components:
- Optimized IP cores
- Tools
- Libraries
- Models
- Example Reference Designs
Inference in machine learning is computation-intensive and requires high memory bandwidth and high performance compute to meet the low-latency and high-throughput requirements of various end applications.
Vitis AI Workflow
Xilinx Vitis AI provides an innovative workflow to deploy deep learning inference applications on Xilinx Deep Learning Processing Unit (DPU) using a simple process:
Source: Xilinx
- The Deep Processing Unit (DPU) is a configurable computation engine optimized for convolution neural networks for deep learning inference applications and placed in programmable logic (PL). DPU contains efficient and scalable IP cores that can be customized to meet many different applications’ needs. The DPU defines its own instruction set, and the Vitis AI compiler generates instructions.
- VITIS AI compiler schedules the instructions in an optimized manner to get the maximum performance possible.
- Typical workflow to run any AI Application on Xilinx ZynqMP UltraScale+ SoC platform comprises:
- Model Quantization
- Model Compilation
- Model Optimization (Optional)
- Build DPU executable
- Build software application
- Integrate VITIS AI Unified APIs
- Compile and link the hybrid DPU application
- Deploy the hybrid DPU executable on FPGA
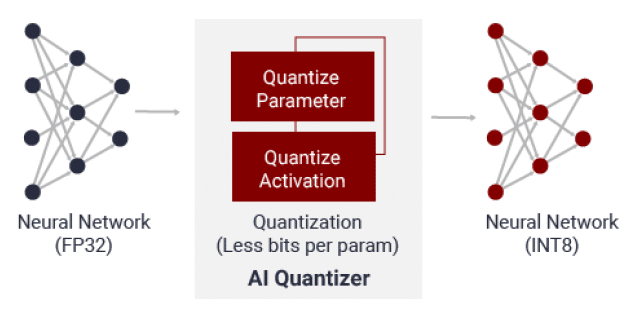
AI Quantizer
AI Quantizer is a compression tool for the quantization process by converting 32-bit floating-point weights and activations to fixed point INT8. It can reduce the computing complexity without losing accurate information for the model. The fixed point model needs less memory, thus providing faster execution and higher power efficiency than floating-point implementation.
AI Quantizer
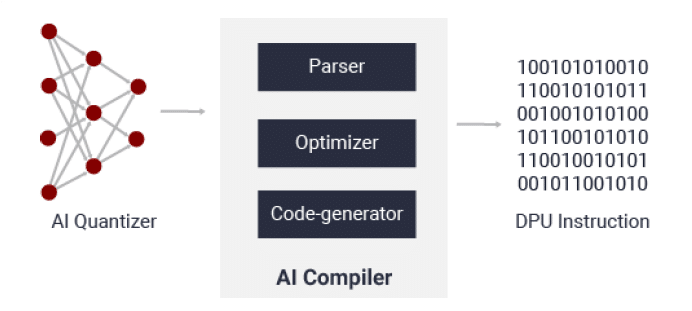
AI Compiler
AI compiler maps a network model to a highly efficient instruction set and data flow. Input to the compiler is Quantized 8-bit neural network, and output is DPU kernel, the executable which will run on the DPU. Here, the unsupported layers need to be deployed in the CPU OR model can be customized to replace and remove those unsupported operations. It also performs sophisticated optimizations such as layer fusion, instruction scheduling and reuses on-chip memory as much as possible.
Once we get Executable for the DPU, one needs to use Vitis AI unified APIs to Initialize the data structure, initialize the DPU, implement the layers not supported by the DPU on CPU & Add the pre-processing and post-processing on a need basis on PL/PS.
AI Compiler
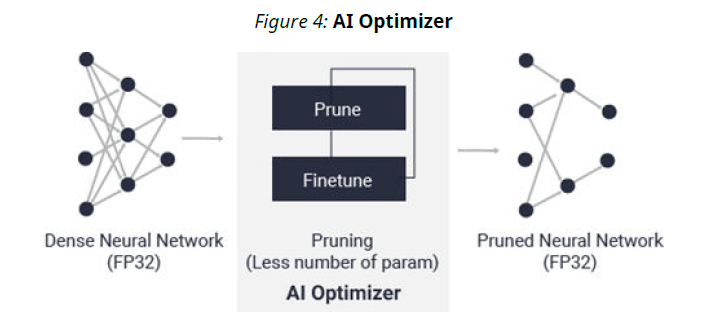
AI Optimiser
With its world-leading model compression technology, AI Optimizer can reduce model complexity by 5x to 50x with minimal impact on accuracy. This deep compression takes inference performance to the next level.
We can achieve desired sparsity and reduce runtime by 2.5x.
AI Optimizer
AI Profiler
AI Profiler can help profiling inference to find caveats causing a bottleneck in the end-to-end pipeline.
Profiler gives a designer a common timeline for DPU/CPU/Memory. This process doesn’t change any code and can also trace the functions and do profiling.
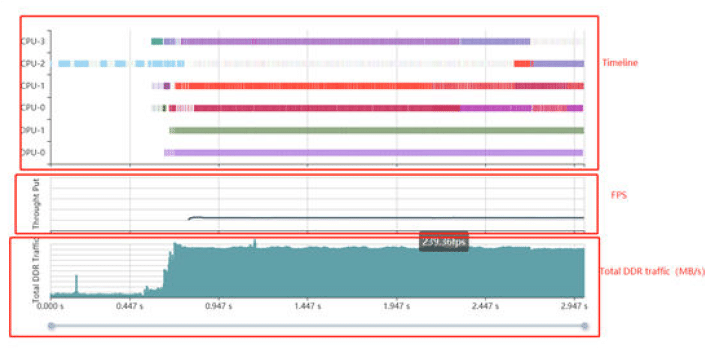
AI Profiler
AI Runtime
VITIS AI runtime (VART) enables applications to use unified high-level runtime APIs for both edge and cloud deployments, making it seamless and efficient. Some of the key features are:
- Asynchronous job submission
- Asynchronous job collection
- C++ and Python implementations
- Multi-threading and multi-process execution
Vitis AI also offers DSight, DExplorer, DDump, & DLet, etc., for various task execution.
DSight & DExplorer
DPU IP offers a number of configurations to specific cores to choose as per the network model. DSight tells us the percentage utilization of each DPU core. It also gives the efficiency of the scheduler so that we could tune user threads. One can also see performance numbers like MOPS, Runtime, memory bandwidth for each layer & each DPU node.
MosChip have a wide range of expertise on various edge and cloud platforms, including vision and image processing on VLIW SIMD vector processor, FPGA, Linux kernel driver development, platform and power management multimedia development. We provide end-to-end ML/AI solutions from dataset preparation to application deployment on edge and cloud and including maintenance.
We chose the Xilinx ZynqMP UltraScale+ platform for high-performance to compute deployments. It provides the best application processing, highly configurable FPGA acceleration capabilities, and VITIS SDK to accelerate high-performance ML/AI inferencing. One such application we targeted was face-mask detection for Covid-19 screening. The intention was to deploy multi-stream inferencing for Covid-19 screening of people wearing masks and identify non-compliance in real time, as mandated by various governments for Covid-19 precautions guidelines.
We prepared a dataset and selected pre-trained weights to design a model for mask detection and screening. We trained and pruned our custom models via the TensorFlow framework. It was a two-stage deployment of face detection followed by mask detection. The trained model thus obtained was passed through VITIS AI workflow covered in earlier sections. We observed 10x speed in inference time as compared to CPU. Xilinx provides different debugging tools and utilities that are very helpful during initial development and deployments. During our initial deployment stage, we were not getting detections for mask and Non-mask categories. We tried to match PC-based inference output with the output from one of the debug utilities called Dexplorer with debug mode & root-caused the issue to debug this further. Upon running the quantizer, we could tune the output with greater calibration images and iterations and get detections with approximation. 96% accuracy on the video feed. We also tried to identify the bottleneck in the pipeline using AI profiler and then taking corrective actions to remove the bottleneck by various means, like using HLS acceleration to compute bottleneck in post-processing.

Face Detection via AI
About MosChip:
MosChip has 20+ years of experience in Semiconductor, Embedded Systems & Software Design, and Product Engineering services with the strength of 1300+ engineers.
Established in 1999, MosChip has development centers in Hyderabad, Bangalore, Pune, and Ahmedabad (India) and a branch office in Santa Clara, USA. Our embedded expertise involves platform enablement (FPGA/ ASIC/ SoC/ processors), firmware and driver development, BSP and board bring-up, OS porting, middleware integration, product re-engineering and sustenance, device and embedded testing, test automation, IoT, AIML solution design and more. Our semiconductor offerings involve silicon design, verification, validation, and turnkey ASIC services. We are also a TSMC DCA (Design Center Alliance) Partner.
Stay current with the latest MosChip updates via LinkedIn, Twitter, FaceBook, Instagram, and YouTube


